
Decoding Token Limits: Navigating ChatGPT's Daily Quotas and What 'Tokens' Really Mean
A guide to understanding Tokens in the world of AI & NLP



By the end of this newsletter you will be able to understand:
The concept of "tokens" in the context of AI and NLP, and how they play a crucial role in processing inputs and generating outputs.
The specific token limits for ChatGPT models, such as GPT-4, and the consequences of exceeding these limits when using the OpenAI API.
Practical tips for developers, including the use of tools like tiktoken to calculate token counts before sending text to the OpenAI API and where to check tier limits on the OpenAI platform.
“You have exhausted token limits of the day, you should come back after 3 hours.”
Tokenization Explained
For Non-Developers: A Simple Overview
In the realm of Artificial Intelligence and Natural Language Processing (NLP), a "token" is essentially the smallest unit of text that a model like GPT (Generative Pre-trained Transformer) can understand and generate. This can range from a word, a part of a word, to even punctuation marks. Think of tokens as the building blocks of language for AI, akin to individual pieces of a puzzle.
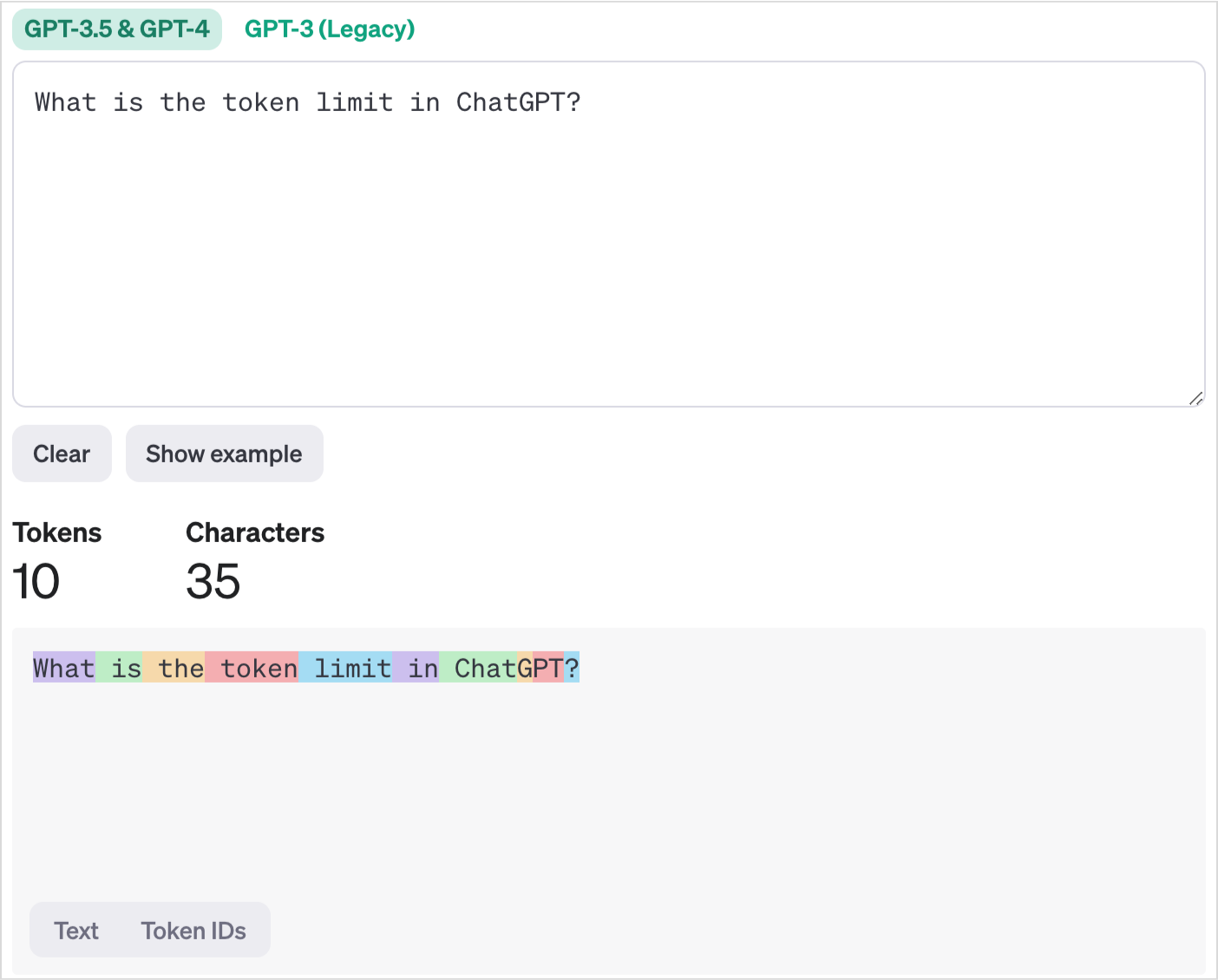
To put it into perspective, let’s visualize tokenization with a simple sentence: “What is the token limit in ChatGPT?” Tokenizing this sentence breaks it down into words: "What", "is", "the", "token", "limit", “in”, “Chat”, , “GPT”, and "?".
Though, this isn’t entirely correct.
In the context of models like GPT, a "token" refers to the smallest unit of text that the “model can understand and generate”. Tokens can be words, parts of words, or even punctuation marks, newline, depending on how the model's tokenizer has been trained.
Advanced tokenizers, especially used in models like GPT-3 or GPT-4, often use subword tokenization techniques. So, they can break words down into smaller pieces, which allows the model to handle a wide variety of words, by combining these pieces in new ways.
In simple words, the sentence “Hello world!” can be broken into multiple tokens( >2).
When we use ChatGPT we give an input, it can be in the form of a text, data sheet etc. And, based on that input, ChatGPT gives us an output. Every input & output consists of a certain number of tokens.
So with every query (input & output) we consume a certain number of tokens.
Now, e.g. if the ChatGPT version you are using has a daily limit of 10k tokens for certain period of time, and you have multiple queries of average 1000 length ( input+output tokens) you can only perform 10000/1000 = 10 queries in that period. So it limits your queries for a certain period.
ChatGPT Plus currently has a cap of 50 messages every 3 hours on GPT-4 and is capped at a 4k context.
A context is the total number of tokens consumed in input(prompt) + output(response) in each query.
Experimentation Tool
Want to experiment yourself and observe the tokenization process in real time? Try out the Tokens Calculator, an official OpenAI tool that allows you to play around and witness how words are broken down into tokens.
Most of the time, there's a common misconception that one token is equivalent to one word. However, tokenization can be more nuanced, especially with complex or longer words.
Give it a try:
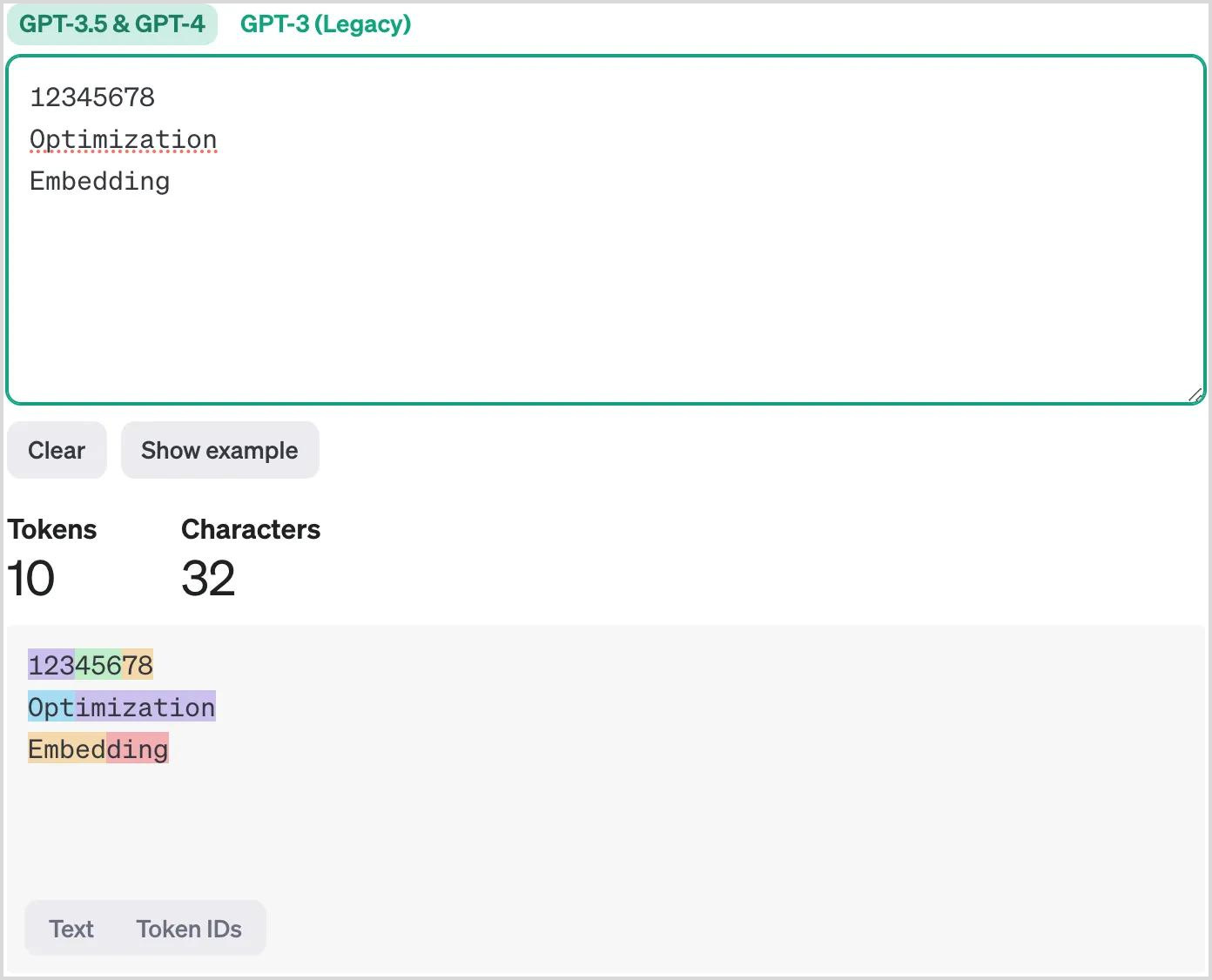
1. 12345678
2. Optimization
3. Embedding
Insert these examples into the tool and see how each sequence is broken down into tokens. It's a valuable exercise to enhance your understanding of tokenization, helping you grasp how input text is processed by OpenAI models.
.
.
.
So, how did it go?
We've also experimented, and it's surprising to see how tokenization can break down seemingly simple words and numbers into multiple tokens. Give it a try and share your thoughts!
Tokenization for Developers
Understanding API Token Limits
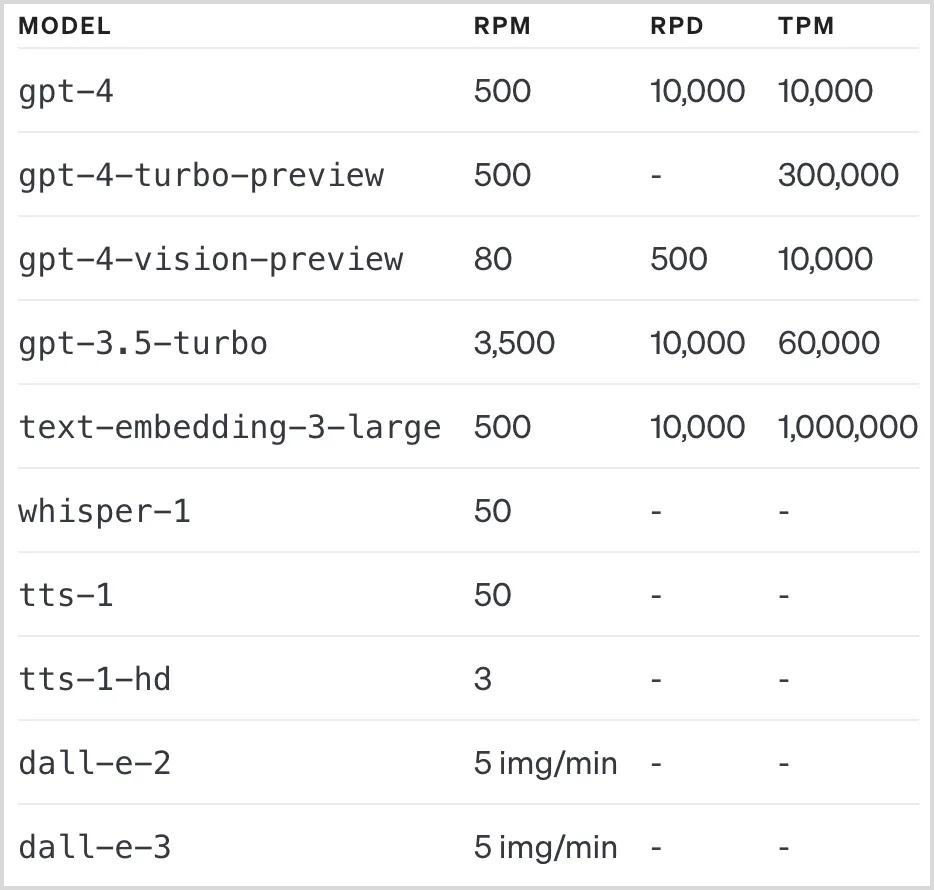
Token limits in OpenAI's API play a crucial role in managing the flow of requests and ensuring the equitable distribution of computational resources among users. Each OpenAI model, such as GPT-4, comes with specific token limitations that users need to be mindful of when sending input to be processed. For instance, GPT-4 has a Token Per Minute (TPM) limit, which caps the number of tokens that can be sent in a single minute to prevent overloading the system.
You might have stumbled upon the token limit with OpenAI APIs, receiving an error like "Token limit exceeded. Reduce the input text and try again." This error occurs when the input tokens given to get a response from the API exceed the token limit.
Understanding Token limits
Token limits are essentially set to prevent any single user from monopolizing the API's resources, which could lead to slower response times for others. The limit of 10,000 tokens per minute for GPT-4, for example, is designed to accommodate a wide range of uses while maintaining efficient service for a broad user base. Exceeding this limit results in an error message advising the user to reduce the input text and try again, ensuring fair access for all users. To understand the tier 1 package for OpenAI Apis and its respective limits refer to the official documentation on OpenAI’s website.
Tools and Strategies for Managing Token Limits
To efficiently manage these limits, developers can use tools like the TikToken Python library (https://pypi.org/project/tiktoken/) or its JavaScript counterpart (https://www.npmjs.com/package/tiktoken).
These tools are designed to estimate the number of tokens in a given input before it's sent to OpenAI, helping to avoid unintentional limit breaches. Additionally, users can monitor their usage through the OpenAI Platform, which offers insights into current token consumption and available limits, tailored to individual or organizational accounts.
When working with the OpenAI API, it's essential to be mindful of the limits imposed on both the number of tokens and the frequency of API calls.
The Broader Applications of Tokenization
Tokenization is not only fundamental to interaction with AI models but also plays a vital role in other areas, including:
RAG Implementation for text encoding and decoding
Vector Databases for efficient information storage and retrieval
Cognitive Architectures to efficiently manage the context and data as memory
Understanding and optimizing token usage is crucial for developers and businesses aiming for cost-effectiveness and smooth AI interactions.
Beyond Limits: Optimization Strategies
Managing your token usage isn't just about staying within limits; it's about cost-effectiveness, especially for developers and businesses. Strategies like summarizing inputs and refining prompts can significantly reduce token consumption, making your interaction with AI not only smoother but also more affordable.
Tokenization isn't just a technical hurdle; it's an integral part of interacting with AI technologies like ChatGPT. By understanding and optimizing your token usage, you're not only avoiding interruptions but also enhancing your overall experience with these powerful tools.
We will try to cover token monitoring, cost efficiency, traffic management and LLMOps in our upcoming articles. Until then,
Happy tokenizing!